
Scaling Down Redshift Clusters and RDS DBs
Overview
- In my team, I have been responsible for migrating the old AWS account to a new account with new environments (dev/staging/uat/prod). The old account was done both through manual creation and CloudFormation.
- My approach to the new account has been done (as much as possible) via Terraform.
- All four envs now look pretty much identical and have the likes of Lambdas, Buckets, Redshift Clusters, RDS DB’s, VPCs etc. all up and running.
However, since this new account isn’t being officially used yet, there is no point having costly AWS features running.
- The biggest expenditures for us are EC2 Instances, Redshift Cluster and RDS DB. We need our instances up always but we decided to control when the Redshift Clusters and RDS DB’s would come on.
- It was decided as follows:
- DEV – Redshift would be paused between 1800-0630 UTC and the RDS DB would be turned on for one hour per day for maintenance reasons
- STAGING – Redshift would be turned off until further notice and the RDS DB would be turned on for one hour per day for maintenance reasons/li>
- UAT – Redshift would be turned off until further notice and the RDS DB would be turned on for one hour per day for maintenance reasons/li>
- PROD – Redshift would be kept on all day and the RDS DB would be turned on for one hour per day for maintenance reasons/li>
- I wasn’t able to find everything I was looking for in one place online to help me solve these issues so hopefully this will help someone in the future that may be looking for a quick fix…
Redshift
- Assuming your Cluster is up and running normally, this is all you need to implement in order to satisfy the above requirements for each env.
Here we have the pause action:
resource "aws_redshift_scheduled_action" "redshift_pause_scheduled_action" {
name = "tf-redshift-pause-scheduled-action"
schedule = "cron(0 18 * * ? *)"
iam_role = aws_iam_role.redshift_pause_resume_role.arn
enable = var.env == "prod" ? false : true
target_action {
pause_cluster {
cluster_identifier = "redshift-cluster-${var.env}"
}
}
}
- The cron job is set to pause the cluster at 1800 UTC each night.
- Since I want to keep the cluster on constantly in prod, there is a conditional statement in there that allows the prod env to ignore the pause action.
- Ensure you put the name of your cluster in the right place.
- In my case, this is done through cluster_identifier = “redshift-cluster-${var.env}”
- The var.env relates to a pre-defined variable:
variable "env" {
description = "Environment infrastructure is being deployed to"
type = string
default = "dev"
}
- Then in my .tfvars file for each env, this variable is hardcoded:
env = "dev"
- Next we have the resume action:
resource "aws_redshift_scheduled_action" "redshift_resume_scheduled_action" {
name = "tf-redshift-resume-scheduled-action"
schedule = "cron(30 6 * * ? *)"
iam_role = aws_iam_role.redshift_pause_resume_role.arn
# enable = var.env == "prod" ? false : true # when we want to start up staging and uat again, use this line and remove one below
enable = var.env == "dev" ? true : false
target_action {
resume_cluster {
cluster_identifier = "redshift-cluster-${var.env}"
}
}
}
- The cron job is set to resume the cluster at 0630 UTC each morning.
- The original conditional statement (which is now commented out for later use) was the same as in the pause schedule where it would only apply to envs that were not prod.
- Now, because we want prod on constantly and we only want dev to resume again (and leave staging/uat paused), I changed the statement to only apply to the dev env since it automatically does not apply to prod since prod was never paused.
- Finally, we have the necessary IAM role to grant permissions allowing the actions to actually pause the cluster:
resource "aws_iam_role" "redshift_pause_resume_role" {
name = "${var.customer_name}-${var.project_name}-redshift-scheduled-action-role-${var.env}"
description = "Redshift Pause Resume Scheduled Role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal = {
Service = "scheduler.redshift.amazonaws.com"
}
Action = "sts:AssumeRole"
},
]
})
path = "/"
managed_policy_arns = [
"arn:aws:iam::aws:policy/AmazonRedshiftFullAccess"
]
}
- Hopefully that was all pretty straightforwards (assuming you are familiar with Terraform and AWS).
RDS DB
- This one was a bit more tricky. It involved creating a lambda in Python, then in Terraform I needed to set up the lambda IaC, IAM permissions and CloudWatch event rules.
- Let’s start with the Python lambda:
import os
import boto3
def lambda_handler(event, context):
rds = boto3.client('rds')
env = os.getenv("env")
db_instance_identifier = f'sql-server-ingestion-data-{env}'
# Check the current state of the RDS instance
response = rds.describe_db_instances(DBInstanceIdentifier=db_instance_identifier)
db_instance = response['DBInstances'][0]
db_instance_status = db_instance['DBInstanceStatus']
# Start the RDS instance if not running
if db_instance_status != 'available':
rds.start_db_instance(DBInstanceIdentifier=db_instance_identifier)
return f"Starting RDS instance: {db_instance_identifier}"
# Stop the RDS instance if running
else:
rds.stop_db_instance(DBInstanceIdentifier=db_instance_identifier)
return f"Stopping RDS instance: {db_instance_identifier}"
- Feel free to use this but remember to set the db_instance_identifier to whatever name yours is called. In my case, the RDS DB is the same across the accounts but with the specific env tacked on to the end each time. I get this from the var.env that is run to ensure the correct DB is queried (as explained in the Redshift Cluster section).
- Basically, at the time of the cron job trigger, the DB will be checked to see if it is active (on). If it is, it gets turned off and at the next cron job trigger, it will check the status, see that it is now active and turn it off etc.
- Here is the IaC lambda set up:
data "archive_file" "rds_start_stop_lambda_archive" {
type = "zip"
source_dir = "src/rds/"
output_path = "archive/rds.zip"
}
resource "aws_lambda_function" "rds_start_stop_lambda" {
depends_on = [data.archive_file.rds_start_stop_lambda_archive]
filename = data.archive_file.rds_start_stop_lambda_archive.output_path
function_name = "${var.customer_name}-${var.project_name}-rds-start-stop-lambda-${var.env}"
description = "Lambda to Start/Stop RDS DB ${var.env}"
role = aws_iam_role.rds_start_stop_lambda_role.arn
handler = "app.lambda_handler"
source_code_hash = data.archive_file.rds_start_stop_lambda_archive.output_base64sha256
runtime = "python3.9"
timeout = 60
memory_size = 128
layers = [
]
environment {
variables = {
"env" = var.env
}
}
}
- Pretty standard Terraform lambda set up. This is a structure I really like and have made it the standard across all the team repos containing IaC.
Next we need the start and stop triggers under the lambda set up above.
- Remember to create two event triggers, one for starting and one for stopping the DB. I completely forgot these and it left me scratching my head for a while.
- Here is the start trigger:
resource "aws_lambda_permission" "rds_start_trigger" {
statement_id = "AllowExecutionFromEventBridgeStart"
action = "lambda:InvokeFunction"
principal = "events.amazonaws.com"
function_name = aws_lambda_function.rds_start_stop_lambda.function_name
source_arn = aws_cloudwatch_event_rule.rds_start_lambda_schedule_rule.arn
}
- And here is the stop trigger:
resource "aws_lambda_permission" "rds_stop_trigger" {
statement_id = "AllowExecutionFromEventBridgeStop"
action = "lambda:InvokeFunction"
principal = "events.amazonaws.com"
function_name = aws_lambda_function.rds_start_stop_lambda.function_name
source_arn = aws_cloudwatch_event_rule.rds_stop_lambda_schedule_rule.arn
}
- Note that the statement_id is different in each trigger (essential). The action and principal values should be the ones I have set in my own code. Attach each trigger to the lambda IaC you created earlier and also attach the respective rule (see next section) to each trigger.
Now we add the CloudWatch start/stop rules and targets.
- Below is the rule and target to start the DB. As you can see, the cron job will trigger at 0800 UTC each day:
# Event for starting RDS DB
resource "aws_cloudwatch_event_rule" "rds_start_lambda_schedule_rule" {
name = "${var.customer_name}-${var.project_name}-rds-start-schedule-rule-${var.env}"
description = "Schedule to start the RDS DB"
schedule_expression = "cron(0 8 * * ? *)"
}
resource "aws_cloudwatch_event_target" "rds_start_lambda_target" {
rule = aws_cloudwatch_event_rule.rds_start_lambda_schedule_rule.name
target_id = "${var.customer_name}-${var.project_name}-rds-start-schedule-target-${var.env}"
arn = aws_lambda_function.rds_start_stop_lambda.arn
}
- Below is the rule and target to stop the DB. As you can see, the cron job will trigger at 0900 UTC each day:
# Event for stopping RDS DB
resource "aws_cloudwatch_event_rule" "rds_stop_lambda_schedule_rule" {
name = "${var.customer_name}-${var.project_name}-rds-stop-schedule-rule-${var.env}"
description = "Schedule to stop the RDS DB"
schedule_expression = "cron(0 9 * * ? *)"
}
resource "aws_cloudwatch_event_target" "rds_stop_lambda_target" {
rule = aws_cloudwatch_event_rule.rds_stop_lambda_schedule_rule.name
target_id = "${var.customer_name}-${var.project_name}-rds-stop-schedule-target-${var.env}"
arn = aws_lambda_function.rds_start_stop_lambda.arn
}
- The reason for this one hour window for the DB in all the envs is to allow for necessary maintenance. I also found that stopping a DB for more than 7 days can be tricky because of this maintenance need.
- Remember to give your rule and target a clearly identifiable name and description and ensure the cron is correct for your intentions. Terraform crons can be different from the standard generators you find online.
- Finally we have the required IAM role and policies to get this all working:
# IAM for starting and stopping RDS DB
resource "aws_iam_role" "rds_start_stop_lambda_role" {
name = "${var.customer_name}-${var.project_name}-rds-start-stop-role-${var.env}"
description = "RDS DB Start Stop Role ${var.env}"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Sid = ""
Principal = {
Service = "lambda.amazonaws.com"
}
}
]
})
path = "/"
managed_policy_arns = [
"arn:aws:iam::aws:policy/AmazonRDSDataFullAccess",
"arn:aws:iam::aws:policy/CloudWatchLogsFullAccess",
"arn:aws:iam::aws:policy/service-role/AWSLambdaRole",
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
]
}
resource "aws_iam_policy" "rds_policy" {
name = "${var.customer_name}-${var.project_name}-rds-policy-${var.env}"
description = "Policy for RDS permissions ${var.env}"
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
"Action" : [
"rds:DescribeDBInstances",
"rds:DescribeDBClusters",
"rds:StartDBInstance",
"rds:StopDBInstance",
"rds:StartDBCluster",
"rds:StopDBCluster",
"rds:ListTagsForResource"
],
Effect = "Allow",
Resource = "arn:aws:rds:eu-west-2:${var.aws_account}:db:*"
}
]
})
}
resource "aws_iam_role_policy_attachment" "describe_db_instances_attachment" {
policy_arn = aws_iam_policy.rds_policy.arn
role = aws_iam_role.rds_start_stop_lambda_role.name
}
- You probably wont need as many managed policy arns as I have put in but I like to cover the bases.
- I have also specified the DB resource arn in the RDS policy for security reasons. Just like with var.env earlier in the article, here I pass in var.aws_account which cycles through the 12 digit AWS account ID assigned to each env in the .tfvars file.
- That is pretty much it!
- Push your code, get it into your environments and check that it all works.
- Below you can see what the status of the Redshift cluster in the dev, staging, uat and prod envs are respectively:
- Redshift Cluster in Dev env:

- Redshift Cluster in Staging env:

- Redshift Cluster in UAT env:

- Redshift Cluster in Prod env:

- And below are some screenshots of the lambda triggers in the Prod env and the (now) status of the RDS DB:
- Status of RDS DB in Prod env after applying the Start/Stop Lambda:
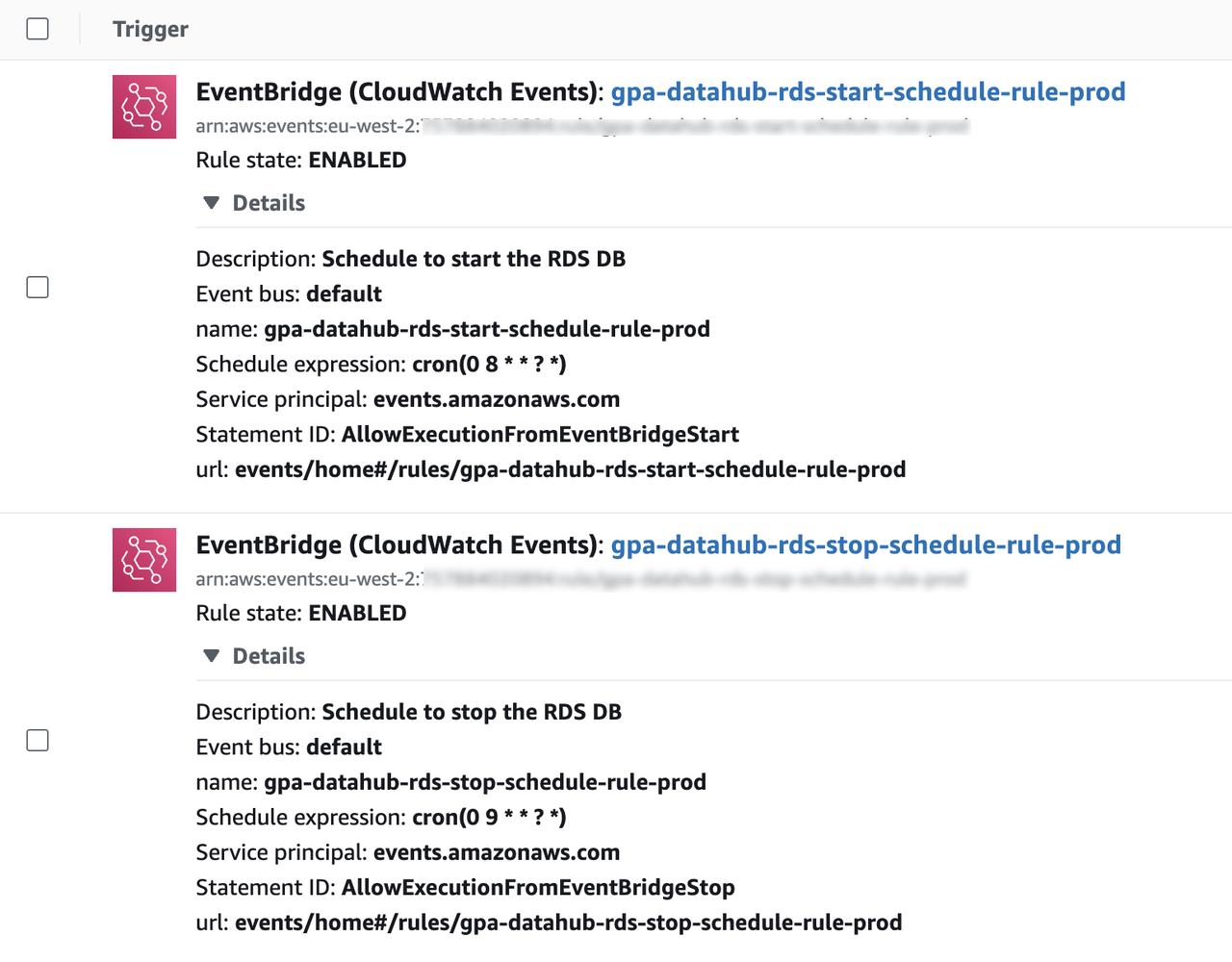
- EventBridge triggers for starting/stopping RDS DB

- I wrote this mostly for my own benefit as this was a good little project I accomplished but since it is such a basic and useful thing to do, I expect others out there will appreciate this easy guide to saving your company money.
- Bring it up as your own idea and take all the praise when you show how much you save the team per month!
Share this article: 



